Database - w2¶
Objective: Using DaanMatch’s Data Model, create a Schema and load DaanMatch data to database.
Patrick Contact Info
OH: Tuesday: 6:30 - 8:00pm PST
guopatrick.comping@gmail.com
Mobile: 5107178380
GitHub: shpatrickguo
This Week’s Objective¶
Get familiar with DaaMatch’s data model, data, GitHub, AWS and your team.
Meiyi (Emily) Ding
emilyding@berkeley.edu GitHub: EmilyDing201
Arthi Matrubutham
apm.butham8@berkeley.edu GitHub: artmatru4b
Apoorv Lawange
apoorv.lawange@berkeley.edu
GitHub: ALaw30
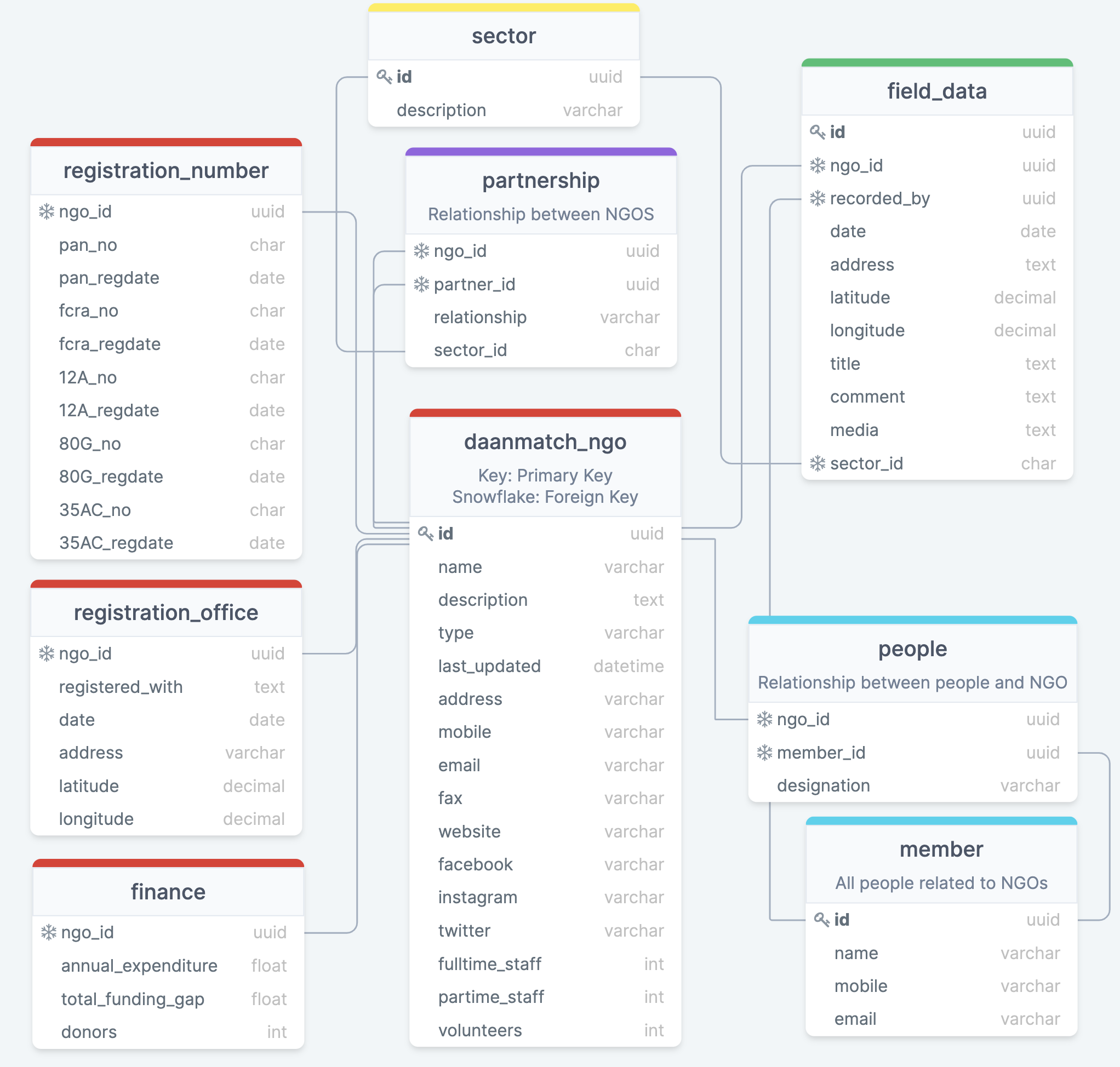
What is a Data model?
A data model is an abstract model that organizes elements of data and standardizes how they relate to one another and to the properties of real-world entities.
What is a Database?
A database is information that is set up for easy access, management and updating.
Git¶
DaanMatch is using GitHub for version control. Code submissions will be done through pull requests.
✅ TODO: To enable effective collaboration please download/review the following
[ ] Download Git
[ ] GitHub Desktop (Optional)
TODO: Clone Data Model
[ ] Create a GitBranch and add your name to CONTRIBUTING.md on Data Model.
How to get our data¶
DaanMatch’s data files are stored on AWS S3.
What is S3?
Amazon Simple Storage Service (Amazon S3) is an object storage service that offers industry-leading scalability, data availability, security, and performance. You can use Amazon S3 to store and retrieve any amount of data at any time, from anywhere.
✅ TODO: Load data from AWS S3 to Jupyter notebook.
Warning
Login information found in #team-shpg on Slack. Please keep login information private.
[ ] Run the following in Jupyter Notebook and submit in shpg-1 folder in Data Model
import pandas as pd
import io
import boto3
client = boto3.client('s3')
obj = client.get_object(Bucket='daanmatchdatafiles', Key='webscrape-fall2021/Final_IndiaNGO.csv')
df = pd.read_csv(io.BytesIO(obj['Body'].read()), low_memory=False)
df.head()
File Assignment¶
Arthi: “giveIndia - giveIndia.csv”
Emily: “InvestIndia.csv”
Apoorv: “helpyourngo.json”
✅ TODO: <2 min presentation about your data